Last Updated on March 2, 2026
Private AI for Word represents the next frontier in data ownership, allowing users to experience a taste of general intelligence directly within their document creation. According to Deep Cogito’s blog, the history of AI breakthroughs—from AlphaGo to the latest reasoning engines—proves that superhuman performance is born from two key ingredients: Advanced Reasoning and Iterative Self-Improvement. Advanced Reasoning allows a system to derive significantly improved solutions simply by increasing its computational “thinking time,” while Iterative Self-Improvement allows it to refine its own intelligence without being strictly bounded by the limitations of a human overseer.
Until recently, most LLMs were trapped by two factors: (1) smaller models could never outsmart the larger ones they were distilled from, and (2) the largest models remained constrained by the human-curated data used to train them. Cogito-v1-preview-qwen-32 breaks this paradigm using Iterated Distillation and Amplification (IDA). Deep Cogito presents an initial approach toward overcoming these constraints via iterative self-improvement in LLMs, integrated with advanced reasoning.

By running GPTLocalhost as an Add-in, you can now deploy this powerful model locally to enable your Private AI for Word. Testing and integrating new LLMs is a core focus of our Ultimate Guide to Local LLMs for Microsoft Word, where we provide the solutions for achieving 100% data ownership.
Watch: Cogito-32B Task Versatility
This demonstration highlights how Cogito-32B handle two different tasks. The first is to compare local LLMs and cloud-based LLMs. The second is to solve a math equation with reasoning.
For more demonstrations of private AI models in Microsoft Word, please visit our channel at @GPTLocalhost.
Technical Profile: Why Cogito-32B for Word? (Download Size: 19.85 GB)
A few months after our test, Cogito released their v2.1 models. According to the latest research from Deep Cogito, “the new models are trained via process supervision for the reasoning chains. As a result, the model develops a stronger intuition for the right search trajectory during the reasoning process, and does not need long reasoning chains to arrive at the correct answer.”
In fact, Cogito v2.1 currently holds the record for the lowest average tokens used with respect to reasoning models of similar capabilities as below.
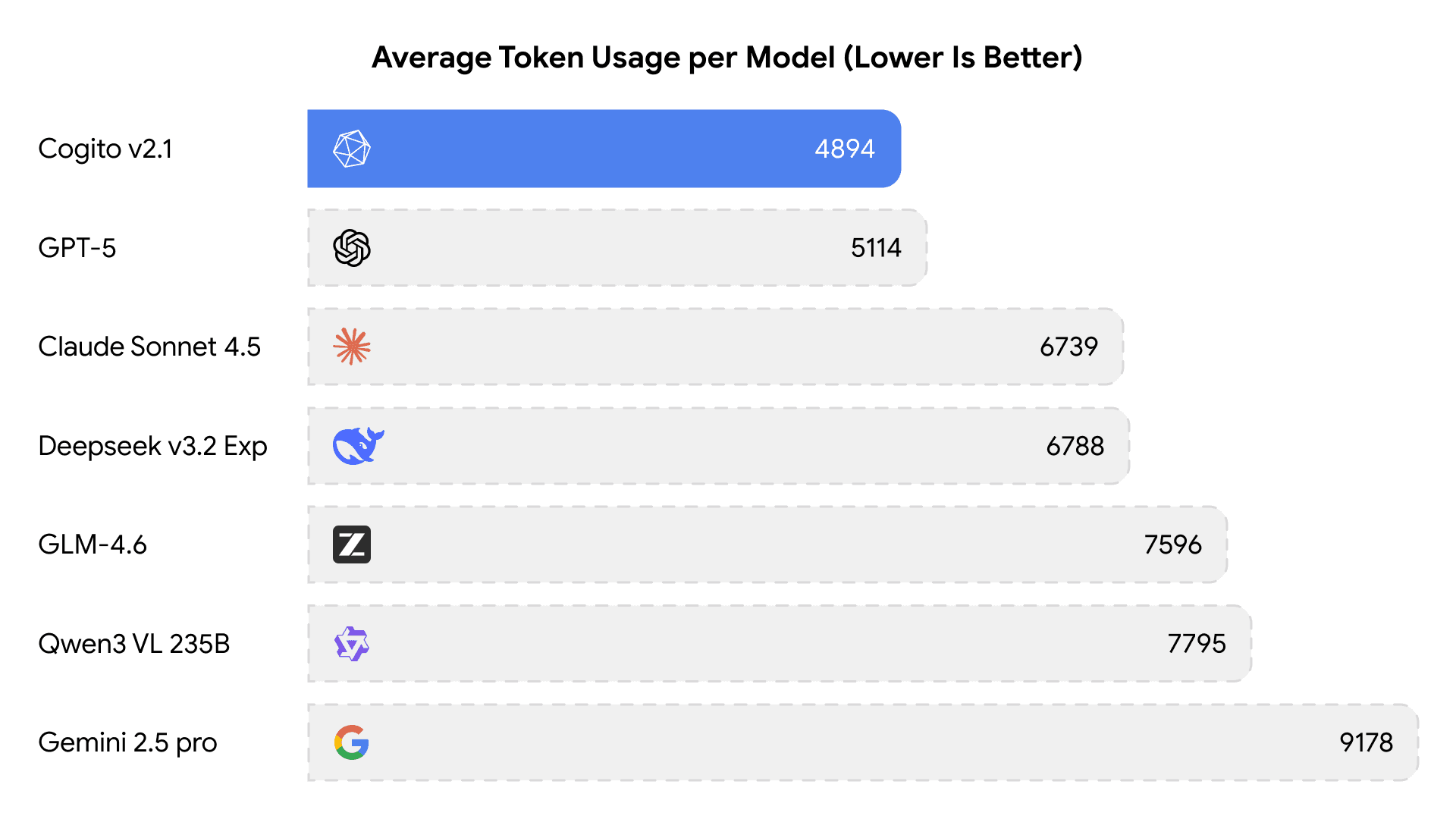
For users in Private AI for Word, this translates to faster response times and lower hardware overhead without compromising on logical depth. Given this breakthrough in efficiency, this series is a potential addition to local toolkit, offering enterprise-grade reasoning that fits comfortably within a local environment.
Deployment Reminders: Running Cogito-32B Locally
Our primary testing was conducted on an M1 Max (64 GB), which is sufficient. To run the Cogito-32B language model locally, the primary hardware requirement is sufficient VRAM (Video RAM) or unified memory, as the model size in its raw format exceeds typical consumer-grade memory capacities. The specific requirement depends heavily on the quantization level used.
- Minimum (Quantized): At least 16 GB to 24 GB for quantized versions (e.g., 4-bit or Q4_K_M), which allows it to run on high-end consumer GPUs like an NVIDIA RTX 3090/4090 (24 GB) or Apple Silicon Macs with 32 GB or more of unified memory.
- System RAM: A minimum of 16 GB of system RAM is recommended, with 32 GB+ for smoother operation, especially if offloading some layers to system RAM.
The Local Advantage
Running Cogito-32B locally via GPTLocalhost ensures:
- Data Ownership: No cloud data leaks.
- Zero Network Latency: Faster performance on GPU and Apple Silicon.
- Offline Access: Work anywhere, including on a plane ✈️, without an internet connection.